
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- GIT
- Excel
- google apps script
- Apache
- 파이썬
- Google Excel
- Redshift
- list
- PANDAS
- matplotlib
- dataframe
- math
- hive
- Google Spreadsheet
- Tkinter
- Java
- Github
- PostgreSQL
- PySpark
- array
- numpy
- django
- gas
- SQL
- Mac
- Kotlin
- Python
- string
- c#
Archives
- Today
- Total
달나라 노트
Python Pandas & openpyxl : column width autofit (column 너비 자동맞춤) 본문
Python/Python Pandas
Python Pandas & openpyxl : column width autofit (column 너비 자동맞춤)
CosmosProject 2024. 2. 26. 23:28728x90
반응형
데이터를 다루다 보면 cell에 길이가 긴 텍스트가 들어갈 수도 있습니다.
이런 경우 column의 너비를 조절해야하는 상황이 생길 수 있는데,
문제는 일일이 컬럼마다 다 너비를 지정해주는건 한계가 있습니다.
그래서 openpyxl의 기능을 이용하여 column width autofit 기능을 구현해봅시다.
import pandas as pd
dict_test = {
'col1': [1, 2, 3, 4, 5],
'col2': ['apple', 'banana', 'aspidfhadinfgkjadnfkskdjnv', 'drizzle', 'electron'],
'col3': [1234, 0.27383720, 39372, None, 102947291.293472],
'col4': [0.9, 0.5238, 0.13, 0.0028, 1024.29278],
}
df_test = pd.DataFrame(dict_test)
xlsx_writer = pd.ExcelWriter('test.xlsx', engine='openpyxl')
df_test.to_excel(xlsx_writer, sheet_name='test', index=False)
worksheet = xlsx_writer.sheets['test']
cls_column = worksheet['B:B'] # B column의 width를 autofit할 것이기 때문에 B column 객체 얻어옴
max_length = 0
for cell in cls_column: # B column에 있는 cell을 하나씩 참조
try: # blank cell에서 값을 참조하려면 error가 발생하기 때문에 try ~ excep 구문 사용
if len(str(cell.value)) > max_length: # 설정한 max_length보다 cell.value가 크면 max_length를 업데이트
max_length = len(str(cell.value))
except:
pass
worksheet.column_dimensions['B'].width = max_length
xlsx_writer.close()
위 코드의 결과는 다음과 같습니다.
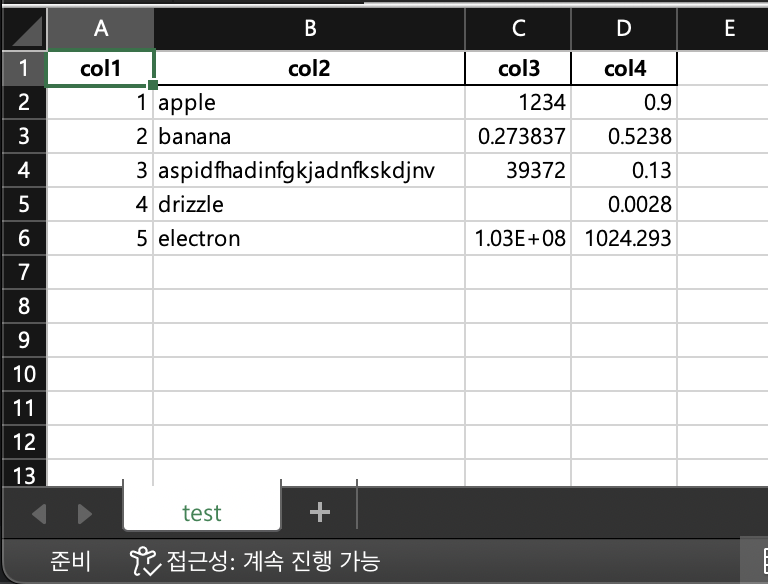
보시면 B4 cell에 좀 긴 텍스트가 담겨있는데
그 텍스트가 잘려서 보이지 않도록 B column width가 적당히 늘어난 것을 볼 수 있습니다.
근데 위 결과를 보면 아직도 C6 cell에 있는 숫자는 column width가 좁아서 잘려보이죠.
아래 코드는 모든 column에 대한 autofit을 구현한 코드입니다.
import pandas as pd
import re
dict_test = {
'col1': [1, 2, 3, 4, 5],
'col2': ['apple', 'banana', 'aspidfhadinfgkjadnfkskdjnv', 'drizzle', 'electron'],
'col3': [1234, 0.27383720, 39372, None, 102947291.293472],
'col4': [0.9, 0.5238, 0.13, 0.0028, 1024.29278],
}
df_test = pd.DataFrame(dict_test)
xlsx_writer = pd.ExcelWriter('test.xlsx', engine='openpyxl')
df_test.to_excel(xlsx_writer, sheet_name='test', index=False)
worksheet = xlsx_writer.sheets['test']
cls_columns = worksheet.columns
for col in cls_columns:
max_length = 0
for cell in col:
try:
if len(str(cell.value)) > max_length:
max_length = len(str(cell.value))
except:
pass
cell_coordinate = cell.coordinate
cell_column = re.sub(r'[0-9]', '', cell_coordinate)
worksheet.column_dimensions[cell_column].width = max_length
xlsx_writer.close()
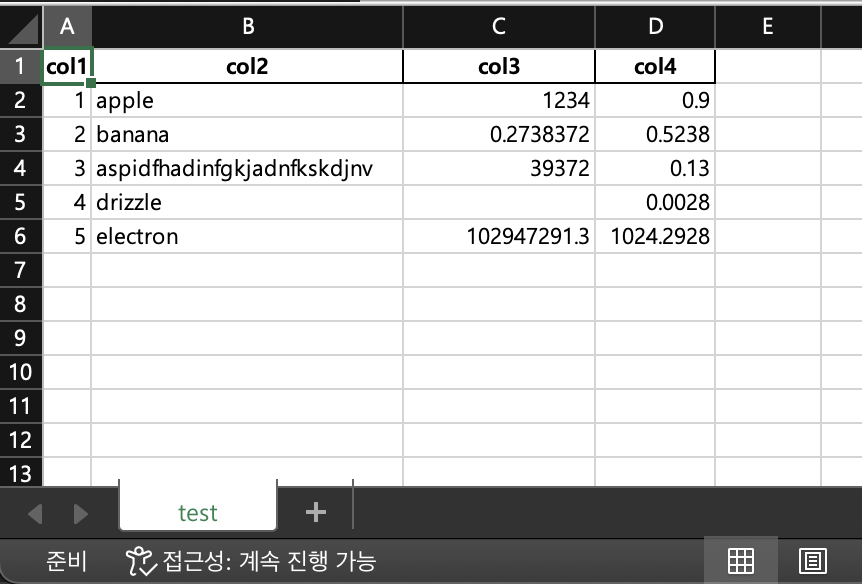
모든 column에 대해 column width가 autofit된 것을 볼 수 있습니다.
728x90
반응형
'Python > Python Pandas' 카테고리의 다른 글
| Python Pandas : Percentile Rank 계산하기 (백분위 계산하기) (0) | 2024.03.25 |
|---|---|
| Python Pandas & openpyxl : alignment (텍스트 정렬) (0) | 2024.02.27 |
| Python Pandas & openpyxl : columns, rows (column에 대한 객체 얻어오기, row에 대한 객체 얻어오기) (0) | 2024.02.26 |
| Python Pandas & openpyxl : font (글자 서식 설정) (2) | 2024.02.26 |
| Python Pandas & openpyxl : fill (셀에 색상 채우기) (0) | 2024.02.26 |
'Python/Python Pandas' Related Articles
more


Comments